
Ultimo aggiornamento: aprile 12, 2024
Disponibile con uno qualsiasi dei seguenti abbonamenti, tranne dove indicato:
|
|
È possibile evitare che i nuovi contenuti appaiano nei risultati aggiungendo lo slug dell'URL a un file robots.txt. I motori di ricerca utilizzano questi file per capire come indicizzare i contenuti di un sito web. I contenuti dei domini del sistema HubSpot sono sempre impostati come no-index in un file robots.txt.
Se i motori di ricerca hanno già indicizzato i contenuti, è possibile aggiungere un meta tag "noindex" all'HTML del contenuto. In questo modo i motori di ricerca smetteranno di visualizzarlo nei risultati di ricerca.
Nota bene: solo i contenuti ospitati su un dominio collegato a HubSpot possono essere bloccati nel file robots.txt. Per saperne di più sulla personalizzazione degli URL dei file nello strumento File.
Utilizzare i file robot.txt
È possibile aggiungere i contenuti non ancora indicizzati dai motori di ricerca a un file robots.txt per evitare che vengano visualizzati nei risultati di ricerca.
Per modificare il file robots.txt in HubSpot:
-
Nel tuo account HubSpot, fai clic sulle icona delle impostazioni nella barra di navigazione principale.
-
Nel menu della barra laterale sinistra, spostarsi su Contenuti > Pagine.
- Selezionare il dominio di cui si desidera modificare il file robots.txt:
- Per modificare il file robots.txt per tutti i domini collegati, fare clic sul menu a discesa Scegli un dominio per modificare le sue impostazioni e selezionare Impostazioni predefinite per tutti i domini.
- Per modificare il file robots.txt per un dominio specifico, fare clic sul menu a discesa Scegli un dominio per modificarne le impostazioni e selezionare il dominio. Se necessario, fare clic su Sovrascrivi impostazioni predefinite. In questo modo si sovrascriveranno le impostazioni predefinite di robots.txt per questo dominio.
- Fare clic sulla scheda SEO e Crawler.
- Nella sezione Robots.txt, modificare il contenuto del file. Il file robots.txt è composto da due parti:.
- User-agent: definisce il motore di ricerca o il bot web a cui si applica una regola. Per impostazione predefinita, viene impostato per includere tutti i motori di ricerca, indicati con un asterisco (*), ma è possibile specificare motori di ricerca specifici. Se si utilizza il modulo di ricerca del sito di HubSpot, è necessario includere HubSpotContentSearchBot come user-agent separato. Ciò consentirà alla funzione di ricerca di effettuare il crawling delle pagine.
-
- Disallow: indica a un motore di ricerca di non eseguire il crawling e l'indicizzazione di file o pagine che utilizzano uno specifico slug URL. Per ogni pagina che si desidera aggiungere al file robots.txt, inserire Disallow: /url-slug ( ad esempio,www.hubspot.com/welcome appare come Disallow: /welcome).
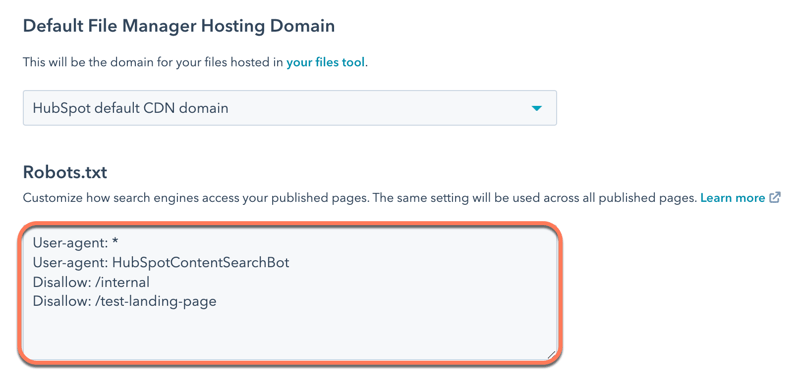
- In basso a sinistra, fare clic su Salva.
Per ulteriori informazioni sulla formattazione di un file robots.txt, consultare la documentazione per sviluppatori di Google.
Utilizzare i meta tag "noindex
Se il contenuto è già stato indicizzato dai motori di ricerca, è possibile aggiungere un meta tag "noindex" per indicare ai motori di ricerca di non indicizzarlo più in futuro.
Attenzione: questo metodo non deve essere combinato con il metodo robots.txt, in quanto impedisce ai motori di ricerca di vedere il tag "noindex".
Aggiungere il meta tag "noindex" a pagine e post
-
Andate al vostro contenuto:
- Pagine del sito web: Nel tuo account HubSpot, passa a Contenuti > Pagine del sito web.
- Pagine di destinazione: Nel tuo account HubSpot, passa a Contenuti > Landing Page.
- Blog: Nel tuo account HubSpot, passa a Contenuti > Blog.
- Passare il mouse sul contenuto e fare clic su Modifica.
- Nell'editor del contenuto, fare clic sul menu Impostazioni e selezionare Avanzate.
- Nella sezione Snippet di codice aggiuntivi della finestra di dialogo, aggiungere il seguente codice al campo Head HTML :
<meta name="robots" content="noindex">.
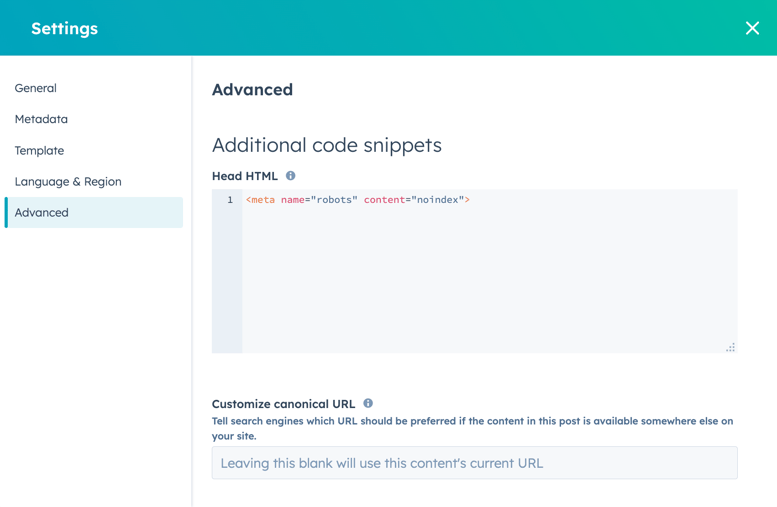
- Per rendere effettiva questa modifica, fare clic su Aggiorna in alto a destra.
Aggiungere i meta tag "noindex" agli articoli della knowledge base
-
Nel tuo account HubSpot, passa a Contenuti > Knowledge Base.
- Passare il mouse sull'articolo e fare clic su Modifica.
- Nell'editor dell'articolo, fare clic sulla scheda Impostazioni, quindi su Opzioni avanzate.
- Nella sezione Snippet di codice aggiuntivi, aggiungere il seguente codice al campo Head HTML :
<meta name="robots" content="noindex">.
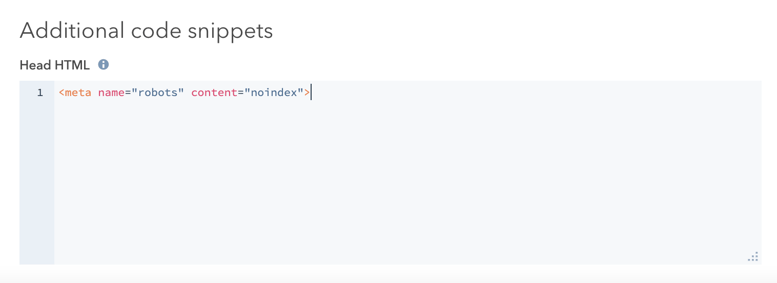
- In alto a destra, fare clic su Aggiorna per rendere effettiva la modifica.
Se si dispone di un account Google Search Console, è possibile accelerare questo processo per i risultati di ricerca di Google con lo Strumento di rimozione di Google.
