
更新日時 2024年 4月 17日
以下の 製品でご利用いただけます(別途記載されている場合を除きます)。
|
|
robots.txtファイルにURLスラッグを追加することで、検索結果に新しいコンテンツが表示されないようにすることができます。検索エンジンは、これらのファイルを使用して、ウェブサイトのコンテンツをインデックス登録する方法を理解します。HubSpotシステムドメインのコンテンツは、robots.txtファイルで常にno-indexに設定されています。
検索エンジンがすでにコンテンツをインデックス登録している場合、コンテンツのヘッドHTMLに「noindex」メタタグを追加することができます。これによって、検索結果にそのコンテンツを表示しないよう検索エンジンに指示されます。
注:robots.txtファイルでブロックできるのは、HubSpotに接続されたドメインでホスティングされているコンテンツのみです。ファイルツールでのファイルURLのカスタマイズについて、詳細をご確認ください。
robot.txtファイルを使用する
まだ検索エンジンによってインデックス登録されていないコンテンツをrobots.txtファイルに追加して、検索結果に表示されないようにすることができます。
HubSpotでrobots.txtファイルを編集するには、次のようにします。
-
HubSpotアカウントにて、上部のナビゲーションバーに表示される設定アイコンをクリックします。
-
左のサイドバーメニューで、[ウェブサイト]>[ページ]の順に進みます。
- そのrobots.txtファイルを編集するドメインを選択します。
- 接続されている全てのドメインのrobots.txtファイルを編集するには、[設定を編集するドメインを選択]ドロップダウンメニューをクリックし、[全てのドメインの既定の設定]を選択します。
- 特定のドメインのrobots.txtファイルを編集するには、[設定を編集するドメインを選択]ドロップダウンメニューをクリックし、ドメインを選択します。必要に応じて、[既定の設定を上書き]をクリックします。このドメインのrobots.txtの既定の設定が上書きされます。
- [SEOおよびクローラー]タブをクリックします。
- [Robots.txt]セクションで、ファイルの内容を編集します。robots.txtファイルには、次の2つの部分で構成されています。
- User-agent:ルールが適用される検索エンジンまたはウェブボットを定義します。既定では、アスタリスク(*)を使用して、全ての検索エンジンを含めるように設定されますが、ここで特定の検索エンジンを指定することもできます。HubSpotのサイト検索モジュールを使用している場合は、「HubSpotContentSearchBot」を別のユーザーエージェントとして含める必要があります。これにより、検索機能がページをクロールできるようになります。
-
- Disallow:検索エンジンに、特定のURLスラッグを使用したファイルやページのクロールおよびインデックス登録を行わないように指示します。robots.txtファイルに追加するページごとに、「Disallow: /url-slug」と入力します(例:「www.hubspot.com/welcome」の場合は「Disallow: /welcome」となります)。
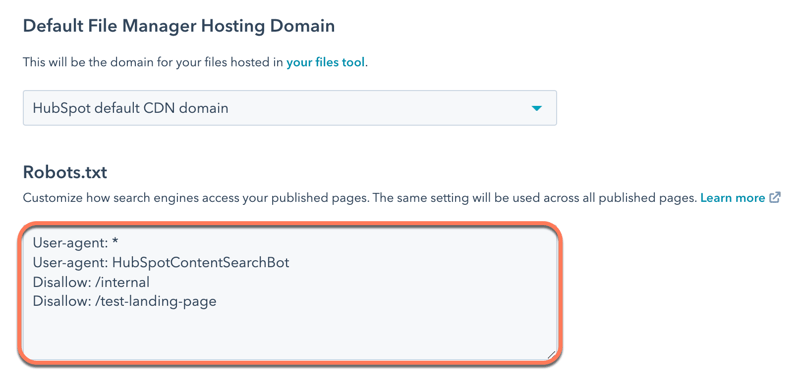
- 左下の[保存]をクリックします。
robots.txtファイルの書式設定について詳しくは、Googleのデベロッパー向けドキュメントをご覧ください。
「noindex」メタタグを使用する
コンテンツが既に検索エンジンにインデックス登録されている場合は、「noindex」メタタグを追加することで、検索エンジンに今後のインデックス登録を停止するよう指示することができます。
注:robots.txtを使用すると、「noindex」タグが検索エンジンに対して非表示になるため、この方法をrobots.txtと併用することはできません。
ページや投稿に「noindex」メタタグを追加する
-
コンテンツを開きます。
- ウェブサイトページ:HubSpotアカウントにて、[コンテンツ]>[ウェブサイトページ]の順に進みます。
- ランディングページ:HubSpotアカウントにて、[コンテンツ]>[ランディングページ]の順に進みます。
- ブログ:HubSpotアカウントにて、[コンテンツ]>[ブログ]の順に進みます。
- コンテンツの上にマウスポインターを置いて、[編集]をクリックします。
- コンテンツエディターで[設定]メニューをクリックし、[詳細]を選択します。
- ダイアログボックスの[追加のコードスニペット]セクションで、[ヘッドHTML]フィールドに以下のコードを追加します:
<meta name="robots" content="noindex">。
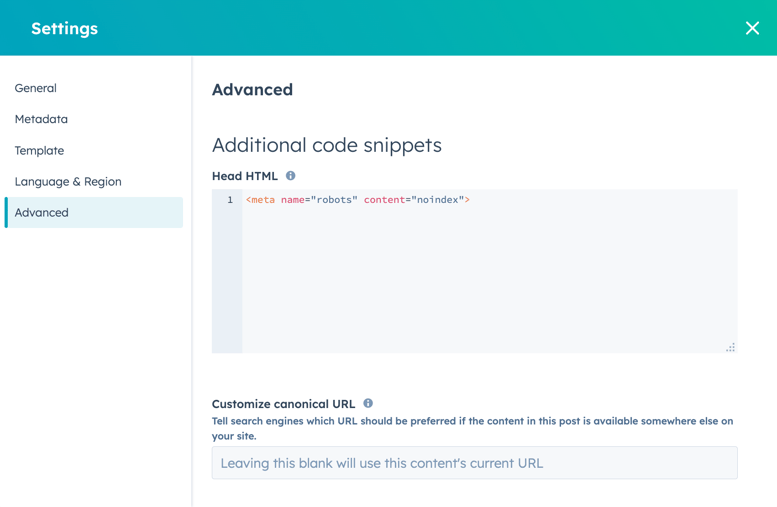
- この変更を有効にするには、右上にある[更新]をクリックします。
ナレッジベース記事に「noindex」メタタグを追加する
-
HubSpotアカウントにて、[コンテンツ]>[ナレッジベース]の順に進みます。
- 記事にマウスポインターを合わせ、「編集」をクリックします。
- 記事エディターで、設定タブをクリックし、詳細オプションをクリックします。
- [追加のコードスニペット]セクションで、[ヘッドHTML]フィールドに以下のコードを追加します:
<meta name="robots" content="noindex">。
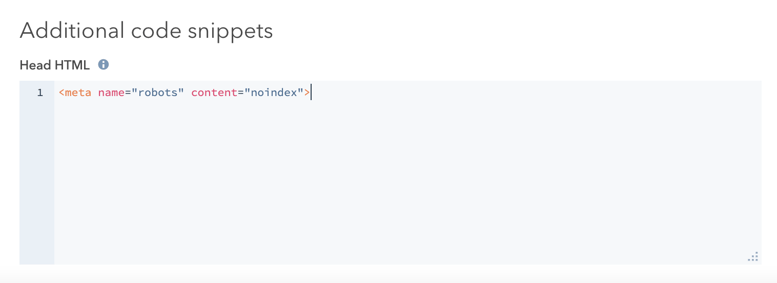
- 右上にある[更新]をクリックして、この変更を反映します。
Google Search Consoleアカウントをお持ちの場合は、Googleの削除ツールを使用すると、このプロセスにかかる時間を短縮できます。
