
Laatst bijgewerkt: april 12, 2024
Beschikbaar met elk van de volgende abonnementen, behalve waar vermeld:
|
|
Je kunt voorkomen dat nieuwe inhoud wordt weergegeven in resultaten door de URL-slug toe te voegen aan een robots.txt-bestand. Zoekmachines gebruiken deze bestanden om te begrijpen hoe ze de inhoud van een website moeten indexeren. Content op HubSpot systeemdomeinen is altijd ingesteld als no-index in een robots.txt bestand.
Als zoekmachines je inhoud al hebben geïndexeerd, kun je een "noindex" metatag toevoegen aan de HTML head van de inhoud. Dit zal zoekmachines vertellen om het niet meer weer te geven in de zoekresultaten.
Let op: alleen inhoud die wordt gehost op een domein dat is verbonden met HubSpot kan worden geblokkeerd in je robots.txt-bestand. Meer informatie over het aanpassen van bestands-URL's in de bestanden-tool.
Gebruik robot.txt bestanden
U kunt inhoud die nog niet is geïndexeerd door zoekmachines toevoegen aan een robots.txt-bestand om te voorkomen dat deze wordt weergegeven in zoekresultaten.
Zo bewerk je je robots.txt-bestand in HubSpot:
-
Klik in je HubSpot-account op het instellingen-pictogram in de bovenste navigatiebalk.
-
Navigeer in het linker zijbalkmenu naar Inhoud > Pagina's.
- Selecteer het domein waarvan je het robots.txt bestand wilt bewerken:
- Om het robots.txt-bestand voor alle verbonden domeinen te bewerken, klik je op het vervolgkeuzemenu Kies een domein om de instellingen te bewerken en selecteer je Standaardinstellingen voor alle domeinen.
- Als u het robots.txt-bestand voor een specifiek domein wilt bewerken, klikt u op het vervolgkeuzemenu Kies een domein om de instellingen te bewerken en selecteert u het domein. Klik indien nodig op Standaardinstellingen overschrijven. Hiermee worden alle standaardinstellingen van robots.txt voor dit domein overschreven.
- Klik op het tabblad SEO & Crawlers.
- Bewerk de inhoud van het bestand in het gedeelte Robots.txt. Er zijn twee delen van een robots.txt-bestand:.
- User-agent: definieert de zoekmachine of webbot waarop een regel van toepassing is. Standaard is dit ingesteld om alle zoekmachines te omvatten, wat wordt weergegeven met een sterretje (*), maar je kunt hier specifieke zoekmachines opgeven. Als je de sitezoekmodule van HubSpot gebruikt, moet je HubSpotContentSearchBot als een aparte user-agent opnemen. Dit zorgt ervoor dat de zoekfunctie je pagina's kan crawlen.
-
- Disallow: vertelt een zoekmachine om geen bestanden of pagina's te crawlen en indexeren die een specifieke URL slug gebruiken. Voer voor elke pagina die je wilt toevoegen aan het robots.txt-bestand Disallow: /url-slug ( www.hubspot.com/welcome zou bijvoorbeeld verschijnen als Disallow: /welcome).
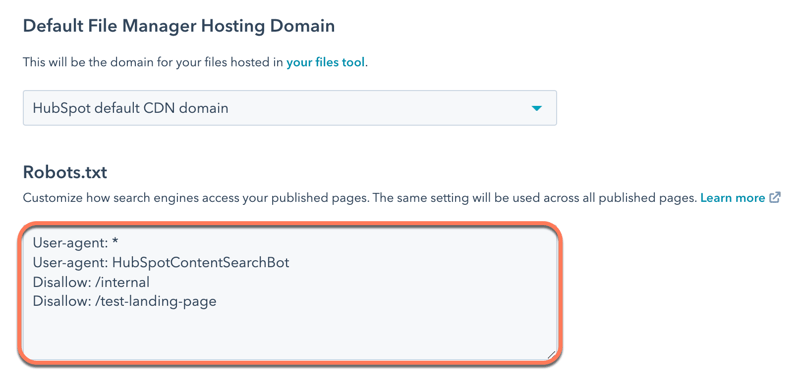
- Klik linksonder op Opslaan.
Meer informatie over het opmaken van een robots.txt-bestand vindt u in de documentatie voor ontwikkelaars van Google.
Gebruik "noindex" metatags
Als inhoud al is geïndexeerd door zoekmachines, kunt u een metatag "noindex" toevoegen om zoekmachines op te dragen deze inhoud in de toekomst niet meer te indexeren.
Let op: deze methode mag niet worden gecombineerd met de robots.txt-methode, omdat zoekmachines de "noindex"-tag dan niet te zien krijgen.
Metatags met "noindex" toevoegen aan pagina's en berichten
-
Navigeer naar uw inhoud:
- Website Pagina's: Ga in je HubSpot-account naar Inhoud > Websitepagina's.
- Landingspagina's: Ga in je HubSpot-account naar Inhoud > Landingspagina's.
- Blog: Ga in je HubSpot-account naar Inhoud > Blog.
- Beweeg de muis over de inhoud en klik op Bewerken.
- Klik in de inhoudseditor op het menu Instellingen en selecteer Geavanceerd.
- Voeg in het gedeelte Extra codesnippers van het dialoogvenster de volgende code toe aan het veld Head HTML :
<meta name="robots" content="noindex">.
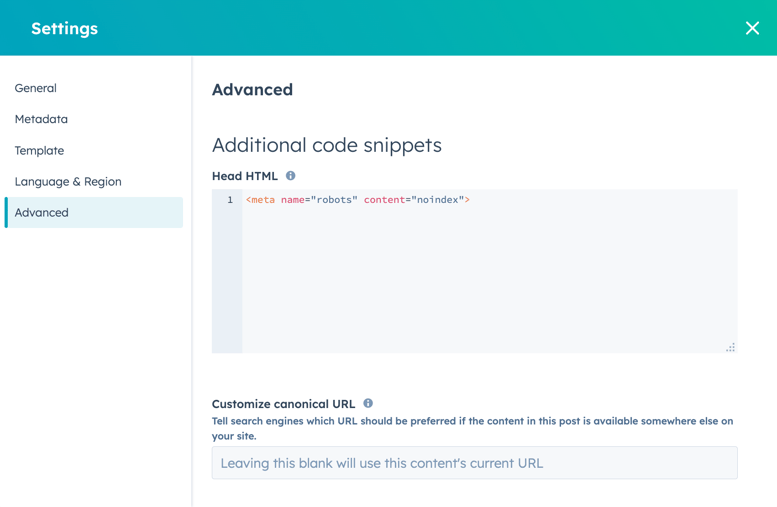
- Klik rechtsboven op Bijwerken om deze wijziging live te zetten.
Metatags "noindex" toevoegen aan kennisbankartikelen
-
Ga in je HubSpot-account naar Inhoud > Kennisdatabase.
- Beweeg de muis over het artikel en klik op Bewerken.
- Klik in de artikeleditor op het tabblad Instellingen en vervolgens op Geavanceerde opties.
- Voeg in de sectie Extra codefragmenten de volgende code toe aan het veld Head HTML :
<meta name="robots" content="noindex">.
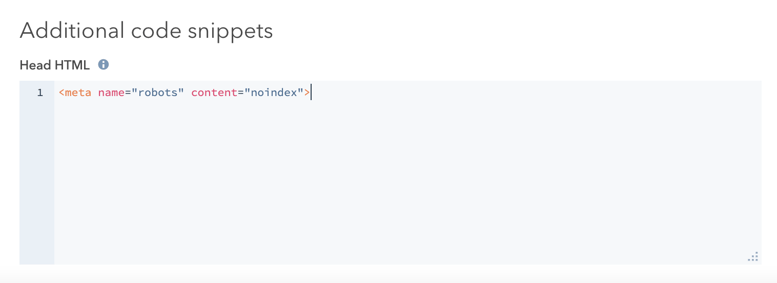
- Klik rechtsboven op Bijwerken om deze wijziging live te zetten.
Als je een Google Search Console-account hebt, kun je dit proces voor Google-zoekresultaten versnellen met de Removals Tool van Google.
