
Ultima atualização: Abril 12, 2024
Disponível com qualquer uma das seguintes assinaturas, salvo menção ao contrário:
|
|
Pode impedir que novos conteúdos apareçam nos resultados, adicionando o slug do URL a um ficheiro robots.txt. Os mecanismos de pesquisa utilizam estes arquivos para saber como indexar o conteúdo de um site. O conteúdo dos domínios do sistema HubSpot é sempre definido como no-index num ficheiro robots.txt.
Se os mecanismos de pesquisa já indexaram o seu conteúdo, você pode adicionar uma meta tag "noindex" ao HTML de cabeçalho do conteúdo. Essa meta tag instruirá os mecanismos de pesquisa a não exibir o conteúdo nos resultados de pesquisa.
Observação: somente conteúdo hospedado em um domínio conectado ao HubSpot poderá ser bloqueado no seu arquivo robots.txt. Saiba mais sobre como personalizar URLs de arquivos na ferramenta de arquivos.
Usar arquivos robot.txt
Você pode adicionar conteúdo que ainda não tenha sido indexado pelos mecanismos de pesquisa a um arquivo robots.txt para impedir que seja exibido nos resultados de pesquisa.
Para editar seu arquivo robots.txt no HubSpot:
-
Na sua conta HubSpot, clique no ícone de settings icon na barra de navegação superior.
-
No menu da barra lateral esquerda, navegue para Conteúdo > Páginas.
- Selecione o domínio cujo arquivo robots.txt você pretende editar:
- Para editar o arquivo robots.txt para todos os domínios conectados, clique no menu suspenso Escolha um domínio para editar suas configurações e selecione Configurações padrão para todos os domínios.
- Para editar o arquivo robots.txt para um domínio específico, clique no menu suspenso Escolha um domínio para editar suas configurações e selecione o domínio. Se necessário, clique em Substituir configurações padrão. Essa ação substituirá quaisquer configurações padrão de robots.txt para este domínio.
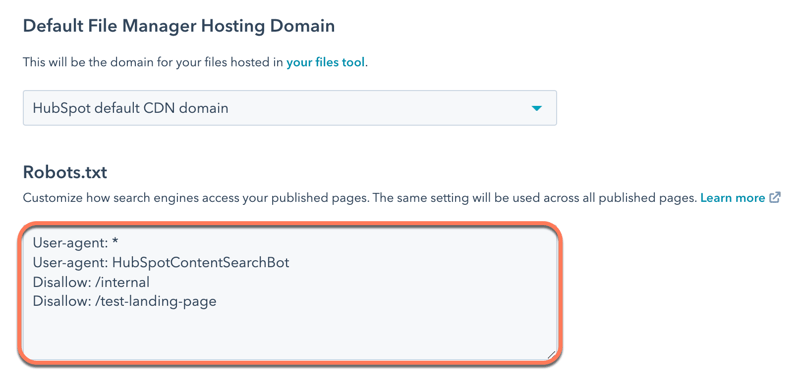
- Clique na guia SEO e rastreadores.
- Na seção Robots.txt, edite o conteúdo do arquivo. Um arquivo robots.txt é composto de duas partes:.
- Agente do usuário: define o mecanismo de pesquisa ou o web bot ao qual uma regra se aplica. Por padrão, isso será definido para incluir todos os mecanismos de pesquisa, o que é mostrado com um asterisco (*), mas você pode especificar mecanismos de pesquisa específicos aqui. Se estiver a utilizar o módulo de pesquisa de sites da HubSpot, terá de incluir HubSpotContentSearchBot como um agente de utilizador separado. Isso permitirá que o recurso de pesquisa rastreie as suas páginas.
-
- Disallow: instrui um mecanismo de pesquisa para não rastrear e indexar arquivos ou páginas que usando um slug de URL específico. Para cada página que você deseja adicionar ao arquivo robots.txt, insira Disallow: /url-slug(por exemplo, www.hubspot.com/welcome apareceria como Disallow: /welcome).
- No canto inferior esquerdo, clique em Salvar.
Saiba mais sobre como formatar o arquivo robots.txt na documentação para desenvolvedores do Google.
Usar meta tags "noindex"
Se o conteúdo já foi indexado pelos mecanismos de pesquisa, você poderá adicionar uma meta tag "noindex" para instruir os mecanismos de pesquisa a pararem de indexá-lo no futuro.
Observe: este método não deve ser combinado com o método robots.txt, pois isso impedirá que os motores de busca vejam a etiqueta "noindex".
Adicionar meta tags "noindex" às páginas e posts
-
Acesse seu conteúdo:
- Páginas do site: Na sua conta da HubSpot, acesse Conteúdo > Páginas do site.
- Landing Pages: Na sua conta da HubSpot, acesse Conteúdo > Landing pages.
- Blog: Na sua conta da HubSpot, acesse Conteúdo > Blog.
- Passe o cursor do mouse sobre o conteúdo e clique em Editar.
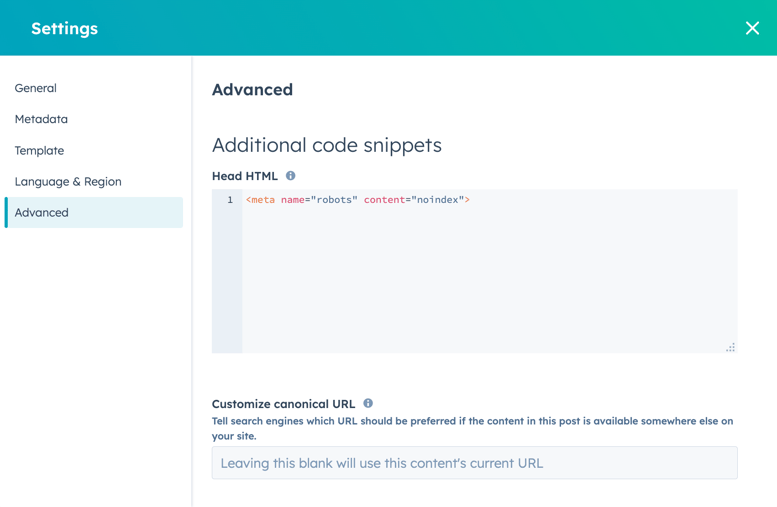
- No editor de conteúdo, clique no menu Configurações e selecione Avançado.
- Na seção Snippets de código adicionais da caixa de diálogo, adicione o seguinte código ao campo HTML do cabeçalho:
<meta name="robots" content="noindex">.
- Para aplicar a alteração, clique em Atualizar no canto superior direito.
Adicionar meta tags "noindex" aos artigos da central de conhecimento
-
Na sua conta da HubSpot, acesse Conteúdo > Central de Conhecimento.
- Passe o cursor do mouse sobre o artigo e clique em Editar.
- No editor de artigos, clique na guia Configurações e em Opções avançadas.
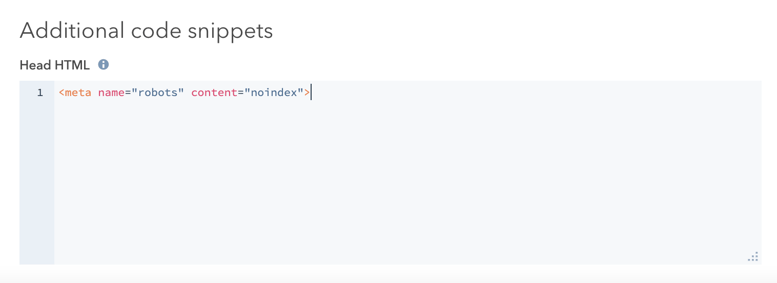
- Na seção Snippets de código adicionais, adicione o seguinte código ao campo HTML do cabeçalho:
<meta name="robots" content="noindex">.
- No canto superior direito, clique em Atualizar para aplicar a alteração.
Se você tiver uma conta no Google Search Console, poderá acelerar esse processo para os resultados de pesquisa do Google usando a Ferramenta de Remoção do Google.
