
Senast uppdaterad: april 12, 2024
Tillgänglig med något av följande abonnemang, om inte annat anges:
|
|
Du kan förhindra att nytt innehåll visas i resultaten genom att lägga till URL-sluggen i en robots.txt-fil. Sökmotorer använder dessa filer för att förstå hur de ska indexera en webbplats innehåll. Innehåll på HubSpot-systemdomäner är alltid inställt som no-index i en robots.txt-fil.
Om sökmotorer redan har indexerat ditt innehåll kan du lägga till en "noindex" metatagg i innehållets head HTML. Detta kommer att tala om för sökmotorer att sluta visa det i sökresultaten.
Observera: Endast innehåll som finns på en domän som är ansluten till HubSpot kan blockeras i din robots.txt-fil. Läs mer om hur du anpassar fil-URL:er i filverktyget.
Använda robot.txt-filer
Du kan lägga till innehåll som ännu inte har indexerats av sökmotorer i en robots.txt-fil för att förhindra att det visas i sökresultaten.
Så här redigerar du din robots.txt-fil i HubSpot:
-
I ditt HubSpot-konto klickar du på inställningsikonen i det övre navigeringsfältet.
-
Gå till Innehåll > Sidor i den vänstra sidomenyn.
- Välj den domän vars robots.txt-fil du vill redigera:
- Om du vill redigera robots.txt-filen för alla anslutna domäner klickar du på Välj en domän för att redigera dess inställningar i rullgardinsmenyn och väljer Standardinställningar för alla domäner.
- Om du vill redigera robots.txt-filen för en specifik domän klickar du på Välj en domän för att redigera dess inställningar och väljer domänen. Om det behövs klickar du på Åsidosätt standardinställningar. Då åsidosätts alla standardinställningar för robots.txt för den här domänen.
- Klicka på fliken SEO och sök robotar.
- I avsnittet Robots.txt redigerar du innehållet i filen. Det finns två delar i en robots.txt-fil:.
- User-agent: definierar den sökmotor eller webbrobot som en regel gäller för. Som standard är detta inställt på att inkludera alla sökmotorer, vilket visas med en asterisk (*), men du kan ange specifika sökmotorer här. Om du använder HubSpots sökmodul för webbplatser måste du inkludera HubSpotContentSearchBot som en separat user-agent. Detta gör det möjligt för sökfunktionen att genomsöka dina sidor.
-
- Disallow: talar om för en sökmotor att inte genomsöka och indexera filer eller sidor som använder en specifik URL-slug. För varje sida som du vill lägga till i robots.txt-filen anger duDisallow: /url-slug ( t.ex. www.hubspot.com/welcome skulle visas som Disallow: /welcome).
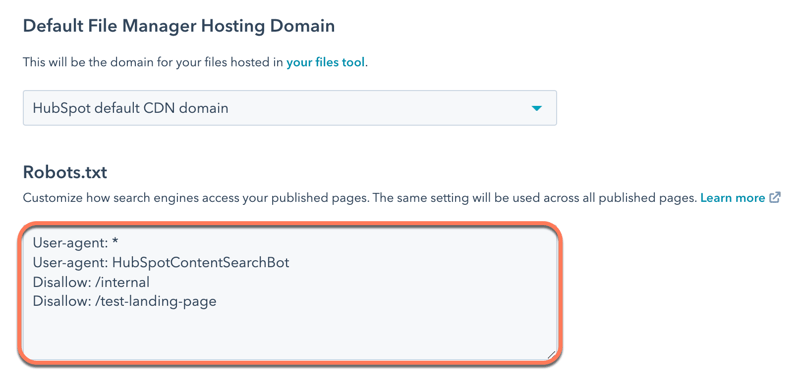
- Klicka på Spara längst ned till vänster.
Läs mer om hur du formaterar en robots.txt-fil i Googles dokumentation för utvecklare.
Använd metataggar för "noindex"
Om innehållet redan har indexerats av sökmotorer kan du lägga till en "noindex"-metatagg för att instruera sökmotorerna att sluta indexera det i framtiden.
Observera: Denna metod bör inte kombineras med robots.txt-metoden, eftersom detta förhindrar sökmotorer från att se "noindex"-taggen.
Lägg till "noindex"-metataggar på sidor och i inlägg
-
Navigera till ditt innehåll:
- Webbplatssidor: I ditt HubSpot-konto navigerar du till Innehåll > Webbplatssidor.
- Landningssidor: I ditt HubSpot-konto navigerar du till Innehåll > Landningssidor.
- Blogg:
- Håll muspekaren över innehållet och klicka på Redigera.
- I innehållsredigeraren klickar du på menyn Inställningar och väljer Avancerat.
- I avsnittet Ytterligare kodavsnitt i dialogrutan lägger du till följande kod i HTML-fältet Head :
<meta name="robots" content="noindex">.
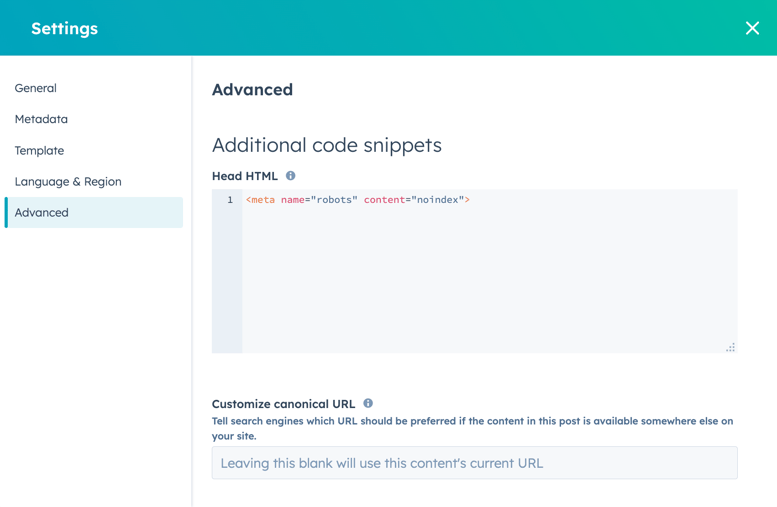
- Klicka på Uppdatera längst upp till höger för att aktivera ändringen.
Lägg till "noindex" metataggar till artiklar i kunskapsbasen
- Håll muspekaren över artikeln och klicka på Redigera.
- Klicka på fliken Inställningar i artikelredigeraren och klicka sedan på Avancerade alternativ.
- I avsnittet Ytterligare kodavsnitt lägger du till följande kod i HTML-fältet Head :
<meta name="robots" content="noindex">.
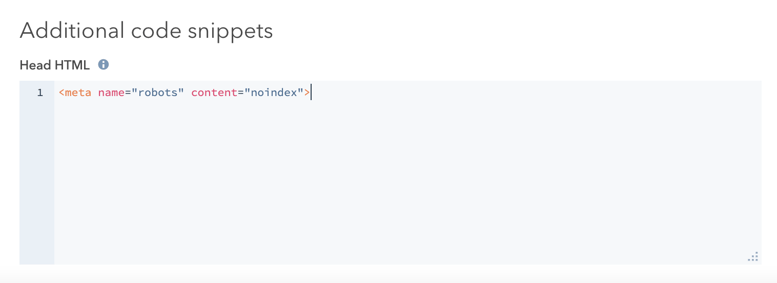
- Klicka på Uppdatera längst upp till höger för att genomföra ändringen.
Om du har ett Google Search Console-konto kan du påskynda denna process för Googles sökresultat med Googles borttagningsverktyg.