
Data ostatniej aktualizacji: kwietnia 12, 2024
Dostępne z każdą z następujących podpisów, z wyjątkiem miejsc, w których zaznaczono:
|
|
Możesz zapobiec pojawianiu się nowych treści w wynikach, dodając slug adresu URL do pliku robots.txt. Wyszukiwarki używają tych plików, aby zrozumieć, jak indeksować zawartość witryny. Zawartość domen systemu HubSpot jest zawsze ustawiona jako no-index w pliku robots.txt.
Jeśli wyszukiwarki już zaindeksowały treść, możesz dodać metatag "noindex" do nagłówka HTML treści. Dzięki temu wyszukiwarki przestaną wyświetlać ją w wynikach wyszukiwania.
Uwaga: tylko treści hostowane w domenie połączonej z HubSpot mogą być blokowane w pliku robots.txt. Dowiedz się więcej o dostosowywaniu adresów URL plików w narzędziu Pliki.
Używanie plików robots.txt
Zawartość, która nie została jeszcze zindeksowana przez wyszukiwarki, można dodać do pliku robots.txt, aby zapobiec wyświetlaniu jej w wynikach wyszukiwania.
Aby edytować plik robots.txt w HubSpot:
-
Na koncie HubSpot kliknij ikonę ustawień w górnym pasku nawigacyjnym..
-
W menu na lewym pasku bocznym przejdź do sekcji Zawartość > Strony.
- Wybierz domenę, której plik robots.txt chcesz edytować:
- Aby edytować plik robots.txt dla wszystkich połączonych domen, kliknij menu rozwijane Wybierz domenę, aby edytować jej ustawienia i wybierz opcję Ustawienia domyślne dla wszystkich domen.
- Aby edytować plik robots.txt dla określonej domeny, kliknij menu rozwijane Wybierz domenę, aby edytować jej ustawienia i wybierz domenę. W razie potrzeby kliknij opcję Zastąp ustawienia domyślne. Spowoduje to zastąpienie domyślnych ustawień pliku robots.txt dla tej domeny.
- Kliknij kartę SEO i roboty indeks ujące.
- W sekcji Robots. txt edytuj zawartość pliku. Istnieją dwie części pliku robots.txt:.
- User-agent: definiuje wyszukiwarkę lub bota internetowego, którego dotyczy reguła. Domyślnie będzie ona obejmować wszystkie wyszukiwarki, co jest oznaczone gwiazdką (*), ale można tu określić konkretne wyszukiwarki. Jeśli korzystasz z modułu wyszukiwania w witrynie HubSpot, musisz dołączyć HubSpotContentSearchBot jako osobnego agenta użytkownika. Umożliwi to funkcji wyszukiwania indeksowanie stron.
-
- Disallow: informuje wyszukiwarkę, aby nie indeksowała żadnych plików ani stron przy użyciu określonego slugu adresu URL. Dla każdej strony, którą chcesz dodać do pliku robots.txt, wpisz Disallow:/url-slug (np. www.hubspot.com/welcome pojawi się jako Disallow : /welcome).
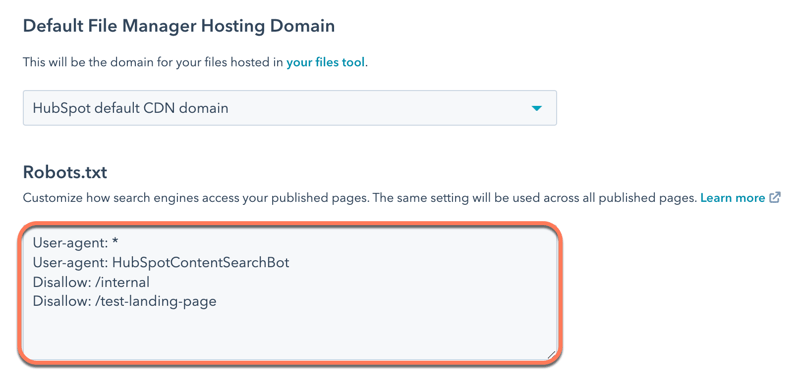
- W lewym dolnym rogu kliknij Zapisz.
Więcej informacji na temat formatowania pliku robots.txt można znaleźć w dokumentacji Google dla programistów.
Używaj metatagów "noindex"
Jeśli treść została już zindeksowana przez wyszukiwarki, możesz dodać metatag "noindex", aby poinstruować wyszukiwarki, aby przestały ją indeksować w przyszłości.
Uwaga: tej metody nie należy łączyć z metodą robots.txt, ponieważ uniemożliwi to wyszukiwarkom zobaczenie tagu "noindex".
Dodawanie metatagów "noindex" do stron i postów
-
Przejdź do treści:
- Strony witryny: Na swoim koncie HubSpot przejdź do Treści > Strony witryny.
- Stronydocelowe: Na swoim koncie HubSpot przejdź do Treści > Strony docelowe.
- Blog: Na swoim koncie HubSpot przejdź do Treści > Blog.
- Najedź kursorem na zawartość i kliknij Edytuj.
- W edytorze treści kliknij menu Ustawienia i wybierz opcję Zaawansowane.
- W sekcji Dodatkowe fragmenty kodu okna dialogowego dodaj następujący kod do pola Head HTML :
<meta name="robots" content="noindex">.
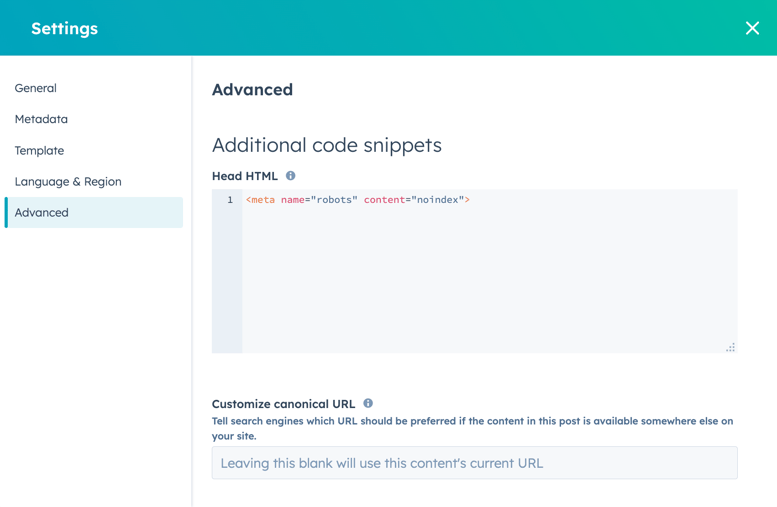
- Aby wprowadzić tę zmianę w życie, kliknij przycisk Aktualizuj w prawym górnym rogu.
Dodawanie metatagów "noindex" do artykułów bazy wiedzy
-
Na swoim koncie HubSpot przejdź do Treści > Baza wiedzy.
- Najedź kursorem na artykuł i kliknij Edytuj.
- W edytorze artykułów kliknij kartę Ustawienia, a następnie kliknij Opcje zaawansowane.
- W sekcji Dodatkowe fragmenty kodu dodaj następujący kod do pola Head HTML :
<meta name="robots" content="noindex">.
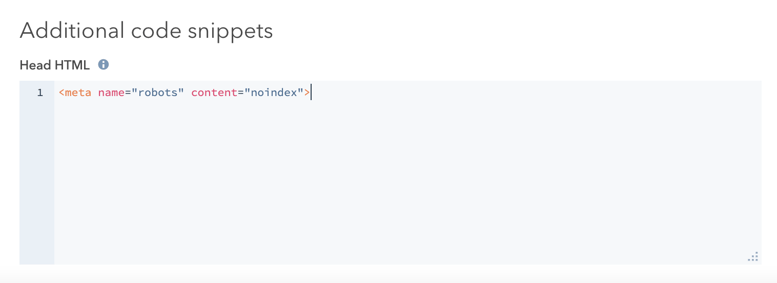
- W prawym górnym rogu kliknij przycisk Aktualizuj , aby wprowadzić tę zmianę.
Jeśli masz konto Google Search Console, możesz przyspieszyć ten proces dla wyników wyszukiwania Google za pomocą Narzędzia usuwania Google.