
Last updated: April 12, 2024
Available with any of the following subscriptions, except where noted:
|
|
You can prevent new content from appearing in results by adding the URL slug to a robots.txt file. Search engines use these files to understand how to index a website's content. Content on HubSpot system domains is always set as no-index in a robots.txt file.
If search engines have already indexed your content, you can add a "noindex" meta tag to the content's head HTML. This will tell search engines to stop displaying it in search results.
Please note: only content hosted on a domain connected to HubSpot can be blocked in your robots.txt file. Learn more about customizing file URLs in the files tool.
Use robot.txt files
You can add content that hasn't yet been indexed by search engines to a robots.txt file to prevent it from being shown in search results.
To edit your robots.txt file in HubSpot:
-
In your HubSpot account, click the settings icon in the top navigation bar.
-
In the left sidebar menu, navigate to Content > Pages.
- Select the domain whose robots.txt file you want to edit:
- To edit the robots.txt file for all connected domains, click the Choose a domain to edit its settings dropdown menu and select Default settings for all domains.
- To edit the robots.txt file for a specific domain, click the Choose a domain to edit its settings dropdown menu and select the domain. If necessary, click Override default settings. This will override any robots.txt default settings for this domain.
- Click the SEO & Crawlers tab.
- In the Robots.txt section, edit the content of the file. There are two parts of a robots.txt file:.
- User-agent: defines the search engine or web bot that a rule applies to. By default, this will be set to include all search engines, which is shown with an asterisk (*), but you can specify specific search engines here. If you're using HubSpot's site search module, you will need to include HubSpotContentSearchBot as a separate user-agent. This will allow the search feature to crawl your pages.
-
- Disallow: tells a search engine not to crawl and index any files or pages using a specific URL slug. For each page you want to add to the robots.txt file, enter Disallow: /url-slug (e.g., www.hubspot.com/welcome would appear as Disallow: /welcome).
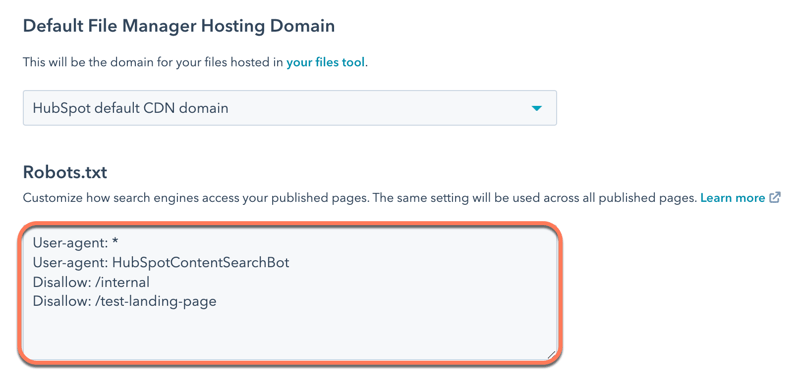
- In the bottom left, click Save.
Learn more about formatting a robots.txt file in Google's developer documentation.
Use "noindex" meta tags
If content has already been indexed by search engines, you can add a "noindex" meta tag to instruct search engines to stop indexing it in the future.
Please note: this method should not be combined with the robots.txt method, as this will prevent search engines from seeing the "noindex" tag.
Add "noindex" meta tags to pages and posts
-
Navigate to your content:
- Website Pages: In your HubSpot account, navigate to Content > Website Pages.
- Landing Pages: In your HubSpot account, navigate to Content > Landing Pages.
- Blog: In your HubSpot account, navigate to Content > Blog.
- Hover over the content and click Edit.
- In the content editor, click the Settings menu and select Advanced.
- In the Additional code snippets section of the dialog box, add the following code to the Head HTML field:
<meta name="robots" content="noindex">.
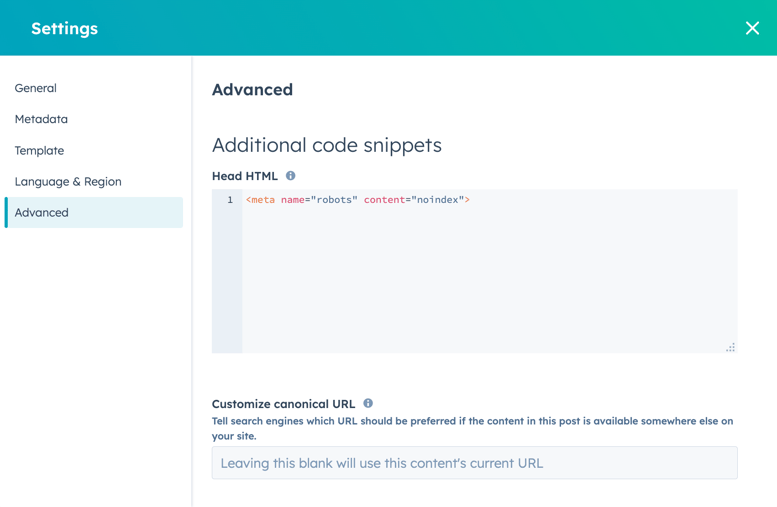
- To take this change live, click Update in the top right.
Add "noindex" meta tags to knowledge base articles
-
In your HubSpot account, navigate to Content > Knowledge Base.
- Hover over the article and click Edit.
- In the article editor, click the Settings tab, then click Advanced Options.
- In the Additional code snippets section, add the following code to the Head HTML field:
<meta name="robots" content="noindex">.
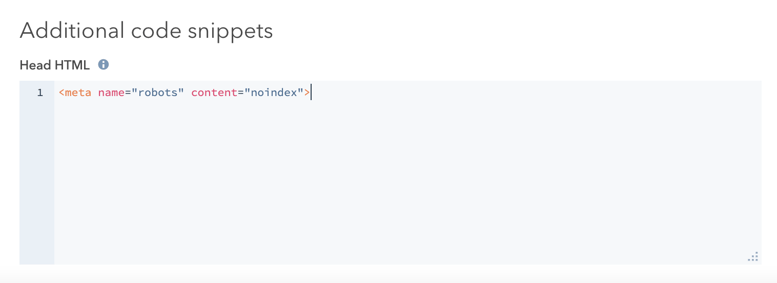
- In the top right, click Update to take this change live.
If you have a Google Search Console account, you can accelerate this process for Google search results with Google's Removals Tool.
