마지막 업데이트 날짜: 2026년 1월 29일
데이터 세트는 사용자 지정 보고서에서 사용할 수 있는 HubSpot 계정 전반의 데이터 모음입니다. 데이터 세트에는 필요에 따라 데이터를 계산하는 공식과 함께 CRM 개체 및 HubSpot 자산에 대한 속성이 포함될 수 있습니다.
요약 기능을 사용하면 데이터 집합 내의 여러 행에 걸쳐 데이터를 집계할 수 있습니다. 또한 요율과 비율을 계산할 수도 있습니다.
요약 함수를 사용하여 계산할 수 있는 지표는 다음과 같습니다:
- 전환율
- 평균 주문 크기
- 평균 마진
- 마감 비율
- 평생 가치
- 고객 확보 비용
- 이탈률
- SLA 준수
- 사용자 지정 NPS 계산
행 수준 공식과 요약 공식 비교
행 수준 수식: 행 수준 연산을 실행하고 단일 레코드에 걸쳐 계산을 수행합니다. 수식 결과에는 행당 하나의 값이 표시되며 계산에 대한 모든 컨텍스트는 행 수준에서 존재합니다. 자세한 내용은 데이터 집합 지식창고의 구문 섹션에서 확인하세요.
요약 수식: 다중 행 데이터 연산을 실행하고 여러 레코드에 걸쳐 메트릭을 계산합니다. 수식 결과에는 행당 하나의 값이 표시되지만 계산의 컨텍스트에는 두 개 이상의 데이터 행이 포함될 수 있습니다.
요약 함수 사용
수식 필드를 만들 때 아래 요약 함수를 사용하여 함수를 만들 수 있습니다:
요약 함수 목록
| 함수 | 정의 | 입력/출력 | 구문 | 예제 |
|
|
지정된 열에 값을 추가하고 집계 값을 반환합니다. |
Input: 숫자/Null 출력: 숫자/Null |
|
|
|
|
주어진 열의 행 수를 반환합니다. |
입력: 숫자/무효 출력: 숫자/공백 |
|
|
|
|
숫자 열의 평균값을 계산합니다. 열의 평균값은 값의 합계를 값의 수로 나눈 값과 같습니다. |
입력: 숫자/공백 출력: 숫자/공백 |
|
|
|
|
주어진 열에서 가장 낮은 값 또는 같은 행에 있는 두 값 사이의 가장 낮은 값을 반환합니다. |
입력: 숫자/날짜/날짜/시간/Null 출력 숫자/날짜/날짜/시간/Null |
|
|
|
|
주어진 열에서 가장 높은 값 또는 같은 행의 두 값 사이에서 가장 높은 값을 반환합니다. |
입력: 숫자/날짜/날짜/시간/Null 출력: 숫자/날짜/시간/Null |
|
|
요약 함수 만들기
요약 함수로 계산된 열은 사용자 지정 보고서 작성기에서 측정값으로 사용할 수 있습니다. 측정값은 차원을 사용하여 세분화할 수 있는 숫자 또는 정량적 값입니다.
데이터 집합 작성기 내에서 요약 측정값은 각 행의 결과를 반복합니다. 보고서 구성에서 측정값의 요약 수준을 정의하는 사용자 지정 보고서 작성기에서 사용할 때까지 계산은 기본적으로 테이블 계산으로 설정됩니다.
데이터 집합의 요약 수식에 대해 자세히 알아보고 예제를 봅니다.
행 수준 요약 결과 만들기
요약 함수를 사용하여 보고 차원을 무시하는 행 수준 결과를 만들 수도 있습니다. 이를 위해서는 FIXED() 함수를 사용해야 합니다.
| 함수 | 입력/출력 | 구문 | 예제 |
|
|
Input: 요약 표현식 출력 행 수준 결과 |
|
|
참고: FIXED() 함수에 정의된 옵션 값이 없는 경우 계산은 테이블 수준에서 계산되며 보고서 뷰의 모든 차원을 무시합니다.
예시
전환 또는 승률 추적
성공률은 총 기회 수 중 성공한 거래의 비율을 나타냅니다. 제품, 시장, 타겟 고객 및 기타 요인을 기준으로 성공률을 추적하면 각 기회에 대한 성공 가능성을 정확히 파악할 수 있습니다. 이를 통해 전환 가능성이 가장 높은 기회에 전략적으로 리소스를 집중할 수 있습니다.
- 데이터 소스가 필요합니다: 거래
- 지표 유형: 유연한 측정 방식
- 공식:
DISTINCT_COUNT(IF(LABEL([DEAL.dealstage]) = "Invoiced", [DEAL.hs_object_id], NULL)) / DISTINCT_COUNT(IF([DEAL.hs_is_closed] = true, [DEAL.hs_object_id], NULL))
데이터 세트 편집기에서 아래 예시를 확인하세요:
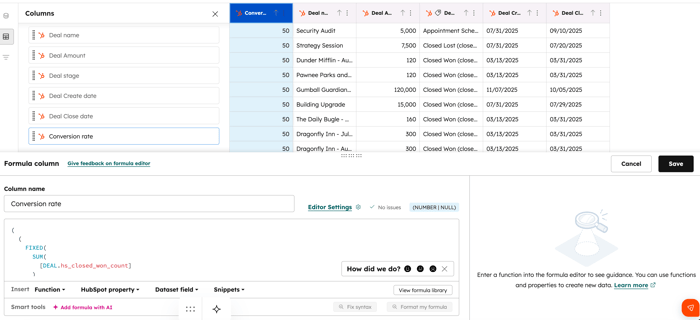
이제 이 전환율 공식이 데이터 세트에 표시되며, 보고서에서 사용할 수 있습니다.
